很惭愧……不知道自己时间都去哪了,今天才发现文件夹里好多写了一半的文章,想把它们补完,一下子又没什么头绪接着写……啊啊啊((٩(//̀Д/́/)۶)) 算了重新写一篇记录一下第一个爬虫练习项目吧~
话不多说,开始吧!
爬取目标
目标是豆瓣电影栏里《逃跑虽可耻但有用》的剧照(Gakki)
看了一下,一共是3268张照片 (╯‵□′)╯︵┻━┻ 身为小白的我一下子就慌了
![不信你看]()
![四倍憋屈]()
好好我先冷静一下,想想啊,为了……(。・∀・)ノ゙怎么也要试一下
目标网址在此!(我选择了按时间排序)
爬取思路
我既然要爬,当然是选择爬高清原图啦!爬小图标算怎么回事呢?打开控制台浏览了一下,到达原图的过程大概是这样的:
首先点击小图标进入普通图标界面,在普通图标界面点击”查看原图”,然后就可以看到我惦记着的高清原图啦!
所以,爬虫的大概思路就有啦,如下:
![gakki大作战流程图1.0.0]()
爬取小图标页面上所有进入普通图标的链接
由下图可以看见,进入普通图标的链接就在 标签中:
![普通图标链接示例]()
所以,只要这样:
1
2
3
4
5
6
7
8
9
10
| import re import requests
from bs4 import BeautifulSoup
url = "https://movie.douban.com/subject/26816519/photos?type=S&start=0&sortby=time&size=a&subtype=a"
def crawl_all_normal_link(current_link):
response = requests.get(url).text
html = BeautifulSoup(response, "html.parser")
link_list_seed = html.findAll("a",{"href":re.compile("https://movie.douban.com/photos/photo/\d{9}$")})
link_list = list()
for temp_link in link_list_seed:
link_list.append(temp_link["href"])
|
比较懒,这里就不写进行异常处理的代码了(好吧我承认我是真的懒)
在普通图标的页面爬取高清原图的链接
以下分别是普通图的链接与高清原图的链接:
https://movie.douban.com/photos/photo/2449245140/
https://img3.doubanio.com/view/photo/raw/public/p2449245140.jpg
看出不同点与共同点了吗??这里有两种方式可以获取高清原图的链接:
- 在小图标界面直接抓取该图片的id,也就是末尾那串数字;然后直接进行字符串拼接,得到高清原图的链接;
- 在普通原图的页面,将cookie写到header里进行get请求(其余必须的header信息也需要写进去);然后利用正则表达式将符合高清原图链接的字符串抓取出来;
我使用的是第二种方法,第一种方法的代码也会在后文给出;
需要注意的是,如果使用第二种方式:
如果不传入cookie,使用正则匹配出来的会是一个锚链接
也就是 ”#“ ,对,就是一个井号~(当时内心:“Excuse me???”)
![Excuse me]()
cookie需要怎么获取呢??
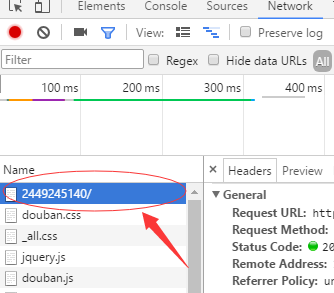
很简单,在普通图标的页面登陆豆瓣之后;然后打开控制台(F12),点击Network:
![Network]()
刷新一下,选择下图中箭头指向的网页:
![当前页面网页]()
在右侧的Requests Headers就可以找到你的cookie,复制下来就行啦~
以下是实现的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| cookie = '''这里放你自己的cookie'''
headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.63 (KHTML, like Gecko) Ubuntu Chromium/55.0.2883.87 Chrome/55.0.2883.87 Safari/573.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br',
'cache-control':'max-age=0',
'referer':'https://movie.douban.com/photos/photo/2403250855/',
'Cookie':cookie
}
'''
函数功能:从中等图标网页,爬取进入高清原图的url
接收参数:URL(字符串类型)
返回值:字符串
'''
def find_real_img_link(url_list):
current_html = requests.get(url_list, headers = headers, stream = True).text
current_html_trans = BeautifulSoup(current_html,"html.parser")
real_img_link_no_trans = current_html_trans.findAll("a",{"class":"photo-zoom"})
real_img_link = list()
for temp_link in real_img_link_no_trans:
real_img_link.append(temp_link["href"])
return real_img_link
|
将高清原图保存到本地
我直接放代码好了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| root = "E://pics//"
'''
函数功能:将图片保存至本地;需要预先设定好root,即存放图片的文件夹的路径
接收参数:URL(字符串类型),无返回值
'''
def save_img(url):
response = requests.get(url, headers = headers, stream = True)
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
with open(path,'wb') as f:
f.write(response.content)
f.close
print("文件保存成功")
else:
print("文件已经存在")
except:
print("爬取失败")
|
爬取下一页的链接
下面是代码👇:
1
2
3
4
5
6
7
8
9
10
11
12
| '''
函数功能:查找下一页的链接的函数
接收参数:URL(字符串类型)
返回值:下一页的链接(字符串类型)
'''
def find_next_link(url):
response_data = requests.get(url, headers = headers, stream = True).text
response = BeautifulSoup(response_data, "html.parser")
next_link_no_trans = response.find("link",{"rel":"next"})
next_link = next_link_no_trans["href"]
return next_link
|
最后
虽然一开始有被吓到,但是冷静下来好好思考的话还是很简单的
中间当然踩了不少坑了,诸如 403 Forbidden 之类的恼人的错误,不过解决过后还是觉得学会了不少哇,嗯咳!作为第一个练习,能完成的像这样也稍微夸夸自己好啦~
不好意思的是:自己总是来不及写博客,总是拖上个十天半个月的……
![真叫人头大]()
希望以后自己的及时学完便记吧!
内容大概就是这些啦,等我将代码整理后会把链接贴上来的吼~
白白~ ヾ(•ω•`)o