嗯,是跟着mooc的视频学的。
觉得看完一部分就该记下来自己学了啥。
好啦,这是魔法师成长日记的第一篇文章~(●ˇ∀ˇ●)
环境准备[Enviornments]
- 安装python3
- 安装pip
- 安装requests库
安装requests库(cmd命令行下):
pip install requests
是不是很简单??o(* ̄▽ ̄ *)ブ
Try to do
先来拿百度试试手吧~
首先打开python的ide:
1 | import requests |
好啦,这时候你会看到一堆数据显示在你的窗口上~
像这样: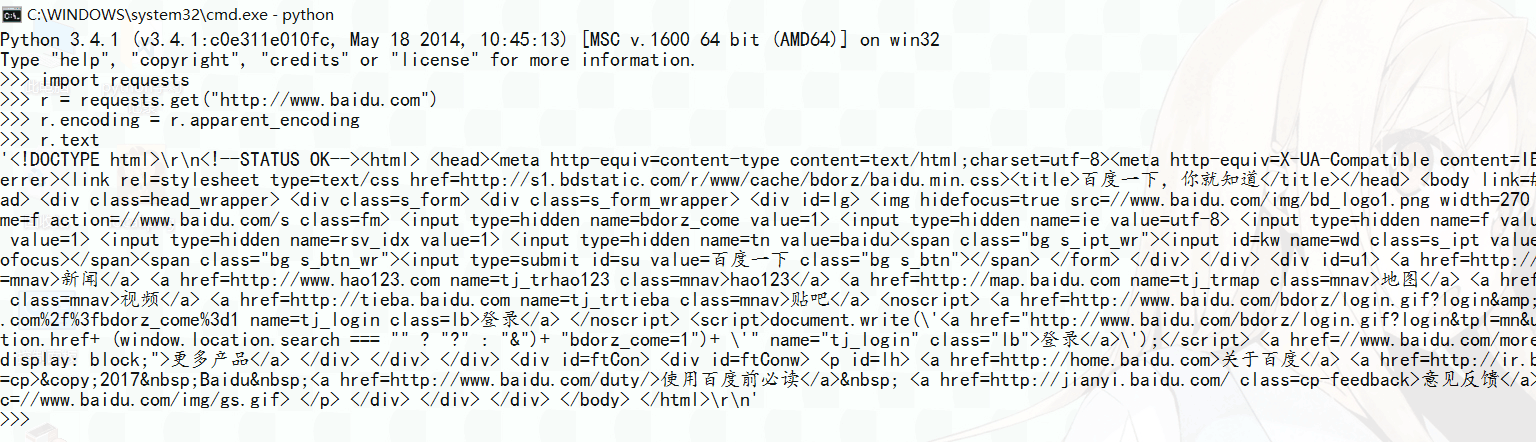
呐,那些数据就是你从百度首页上爬下来的东东啦~
是你第一个手动完成的最简单的一个爬虫哦~(●ˇ∀ˇ●)

Go forward
不过呢,有时候还是会碰见一些无法访问网页的情况吧?这时候我们怎么处理呢?
我们可以在cmd中输出 r.status_code 的值来看,如果返回值不是200的话,意味着你访问失败啦。
但是,那是在命令行中的办法,如果在程序中,我们该肿么办?
可以这样:
1 | import requests |
(当然啦,一般 exception 还是要精准捕获异常的,这里是简单的示范啦 )
如果你用的是vscode的话,且恰好安装了python插件的话,直接右键 Run Python File in Terminal 就可以看到运行结果咯~是不是发现跟第一个例子中输出的数据是一样的呀?
End
现在,给出requests库的常用的六个基础方法吧~
1 | requests.request() |
是不是很好奇这些命令都能做些什么呢?去翻翻看requests的文档吧~
好啦,这就是本篇文章的全部内容啦~感谢你的阅读~
See you then~
